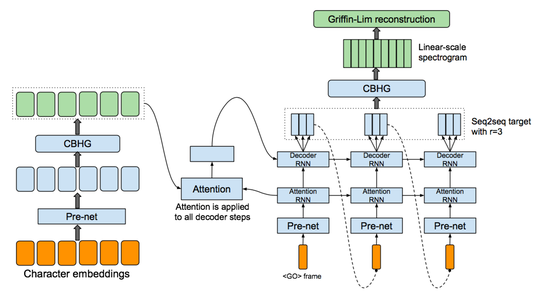
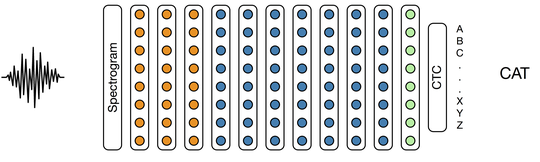
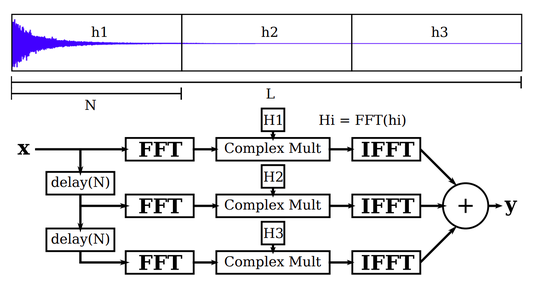
Biography
I joined Google Research in 2017, where I am a part of the Sound Understanding team within Machine Perception. I am passionate about the potential for machine perception research to make our interactions with technology more natural and seamless, rather than distracting and addictive.
Previously, I was a Research Scientist at the Baidu Silicon Valley Artificial Intelligence Lab (SVAIL) led by Adam Coates and Andrew Ng. At Baidu, I had the privilege of contributing to Deep Speech 2, a revolutionary end-to-end neural speech recognition system. Before that, I developed algorithms for audio event detection and music mood classification at Gracenote in Emeryville, CA.
I received my PhD in Electrical Engineering and Computer Sciences from UC Berkeley, where I worked on signal processing and machine learning techniques for music and audio applications as a member of the Parallel Computing Laboratory (Par Lab). For my thesis work, I developed a system for machine understanding of drum performances.
At Berkeley, I was advised by David Wessel at the Center for New Music and Audio Technologies (CNMAT) and co-advised by Nelson Morgan at the International Computer Science Institute (ICSI).
Interests
- Speech Synthesis
- Generative Modeling
- Machine Perception
- Speech and Language Understanding
- Deep Learning / Neural Networks
- Audio Signal Processing
- Parallel Computing
Education
-
PhD in Electrical Engineering and Computer Sciences, 2012
University of California, Berkeley
-
MS in Electrical Engineering and Computer Sciences, 2008
University of California, Berkeley
-
BS in Electrical Engineering, 2005
University of California, Santa Barbara